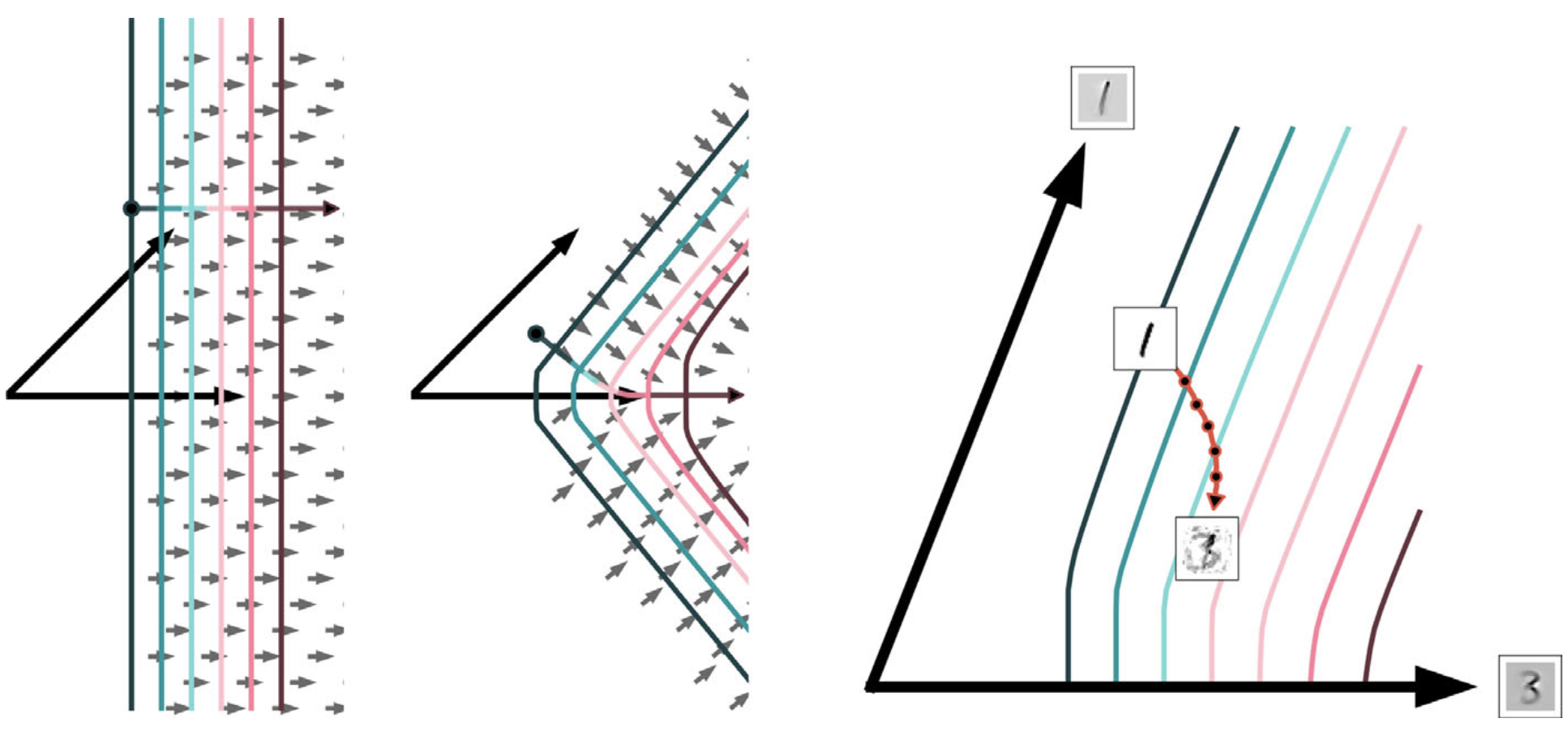
Using differential geometry we explain how sparse coding networks bend their response surfaces, which results in improved selectivity and robustness for individual neurons.
Published in International Conference on Learning Representations, 2021
We construct and analyze new datasets for evaluating disentanglement on natural videos. We also propose a temporally sparse prior for identifying the underlying factors of variation in natural videos.
We construct an unsupervised learning model that achieves nonlinear disentanglement of underlying factors of variation in naturalistic videos. Previous work suggests that representations can be disentangled if all but a few factors in the environment stay constant at any point in time. As a result, algorithms proposed for this problem have only been tested on carefully constructed datasets with this exact property, leaving it unclear whether they will transfer to natural scenes. Here we provide evidence that objects in segmented natural movies undergo transitions that are typically small in magnitude with occasional large jumps, which is characteristic of a temporally sparse distribution. We leverage this finding and present SlowVAE, a model for unsupervised representation learning that uses a sparse prior on temporally adjacent observations to disentangle generative factors without any assumptions on the number of changing factors. We provide a proof of identifiability and show that the model reliably learns disentangled representations on several established benchmark datasets, often surpassing the current state-of-the-art. We additionally demonstrate transferability towards video datasets with natural dynamics, Natural Sprites and KITTI Masks, which we contribute as benchmarks for guiding disentanglement research towards more natural data domains.
We introduce subspace locally competitive algorithms (SLCAs), a family of novel network architectures for modeling latent representations of natural signals with group sparse structure. SLCA first layer neurons are derived from locally competitive algorithms, which produce responses and learn representations that are well matched to both the linear and non-linear properties observed in simple cells in layer 4 of primary visual cortex (area V1). SLCA incorporates a second layer of neurons which produce approximately invariant responses to signal variations that are linear in their corresponding subspaces, such as phase shifts, resembling a hallmark characteristic of complex cells in V1. We provide a practical analysis of training parameter settings, explore the features and invariances learned, and finally compare the model to single-layer sparse coding and to independent subspace analysis.